The professionals And Cons Of Deepseek
페이지 정보

본문
 DeepSeek models and their derivatives are all out there for public obtain on Hugging Face, a prominent site for sharing AI/ML models. DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from Qwen-2.5 collection, which are initially licensed beneath Apache 2.Zero License, and now finetuned with 800k samples curated with DeepSeek-R1. DeepSeek-R1-Zero & DeepSeek-R1 are educated primarily based on DeepSeek-V3-Base. But as we have now written earlier than at CMP, biases in Chinese models not only conform to an data system that's tightly controlled by the Chinese Communist Party, however are additionally expected. Stewart Baker, a Washington, D.C.-primarily based lawyer and advisor who has beforehand served as a top official at the Department of Homeland Security and the National Security Agency, stated DeepSeek "raises all of the TikTok considerations plus you’re talking about data that is extremely prone to be of extra nationwide security and personal significance than anything people do on TikTok," one of many world’s most popular social media platforms.
DeepSeek models and their derivatives are all out there for public obtain on Hugging Face, a prominent site for sharing AI/ML models. DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from Qwen-2.5 collection, which are initially licensed beneath Apache 2.Zero License, and now finetuned with 800k samples curated with DeepSeek-R1. DeepSeek-R1-Zero & DeepSeek-R1 are educated primarily based on DeepSeek-V3-Base. But as we have now written earlier than at CMP, biases in Chinese models not only conform to an data system that's tightly controlled by the Chinese Communist Party, however are additionally expected. Stewart Baker, a Washington, D.C.-primarily based lawyer and advisor who has beforehand served as a top official at the Department of Homeland Security and the National Security Agency, stated DeepSeek "raises all of the TikTok considerations plus you’re talking about data that is extremely prone to be of extra nationwide security and personal significance than anything people do on TikTok," one of many world’s most popular social media platforms.
This document is the primary source of information for the podcast. DeepSeek, right now, has a form of idealistic aura harking back to the early days of OpenAI, and it’s open supply. We're conscious that some researchers have the technical capability to reproduce and open source our results. As an illustration, virtually any English request made to an LLM requires the mannequin to know the way to talk English, but nearly no request made to an LLM would require it to know who the King of France was in the yr 1510. So it’s fairly plausible the optimum MoE should have a couple of specialists which are accessed quite a bit and store "common information", while having others which are accessed sparsely and retailer "specialized information". We will generate a few tokens in every ahead pass and then show them to the mannequin to decide from which point we need to reject the proposed continuation. If e.g. every subsequent token provides us a 15% relative reduction in acceptance, it may be doable to squeeze out some extra achieve from this speculative decoding setup by predicting a few more tokens out. So, for example, a $1M model may clear up 20% of vital coding tasks, a $10M would possibly clear up 40%, $100M might remedy 60%, and so forth.
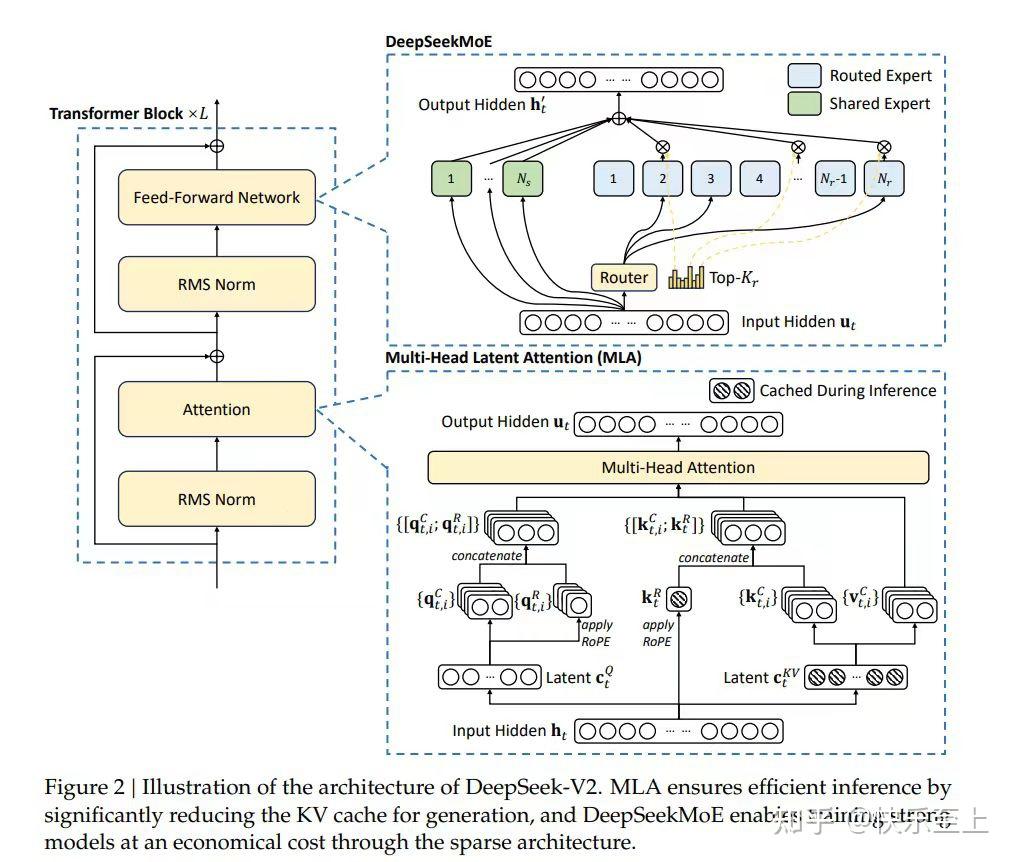
This underscores the strong capabilities of DeepSeek-V3, particularly in dealing with complex prompts, including coding and debugging tasks. Various corporations, including Amazon Web Services, Toyota, and Stripe, are seeking to make use of the model in their program. This half was a giant shock for me as well, to make certain, but the numbers are plausible. Note that, as part of its reasoning and take a look at-time scaling process, DeepSeek-R1 usually generates many output tokens. To do this, DeepSeek-R1 makes use of take a look at-time scaling, a brand new scaling law that enhances a model’s capabilities and deduction powers by allocating further computational sources throughout inference. These two architectures have been validated in DeepSeek-V2 (DeepSeek-AI, 2024c), demonstrating their capability to maintain robust mannequin efficiency whereas reaching efficient coaching and inference. The payoffs from each model and infrastructure optimization additionally suggest there are important beneficial properties to be had from exploring different approaches to inference specifically. So are we close to AGI?
These bias phrases are not updated by way of gradient descent however are as a substitute adjusted throughout training to make sure load stability: if a particular expert just isn't getting as many hits as we predict it should, then we will barely bump up its bias term by a fixed small amount each gradient step till it does. The NIM used for each type of processing might be simply switched to any remotely or domestically deployed NIM endpoint, as explained in subsequent sections. 3. The agentic workflow for this blueprint depends on several LLM NIM endpoints to iteratively process the documents, together with: - A reasoning NIM for DeepSeek Chat doc summarization, raw outline era and dialogue synthesis. Notice, within the screenshot under, which you can see DeepSeek's "thought course of" as it figures out the answer, which is perhaps much more fascinating than the reply itself. You may build AI brokers that ship fast, correct reasoning in real-world applications by combining the reasoning prowess of DeepSeek-R1 with the versatile, secure deployment supplied by NVIDIA NIM microservices.
In case you have almost any questions relating to in which in addition to the way to make use of Deep seek, you can contact us from our own site.
- 이전글The gas market has seen a significant surge over the past decade, due to increasing demand for energy equipment increasing to cater to the expanding oil and gas industry. Among the leading manufacturers specializing in gas detection are Russian companies 25.03.21
- 다음글Най-високото качество - трюфел продукти произведени в Италия 25.03.21
댓글목록
등록된 댓글이 없습니다.